Workflow vs Agent
I am currently building an IM Agent platform for internal engineering collaboration. The platform helps backend engineers and product managers manage requirement context in IM, and then uses agents to implement frontend changes.
It looks like this:
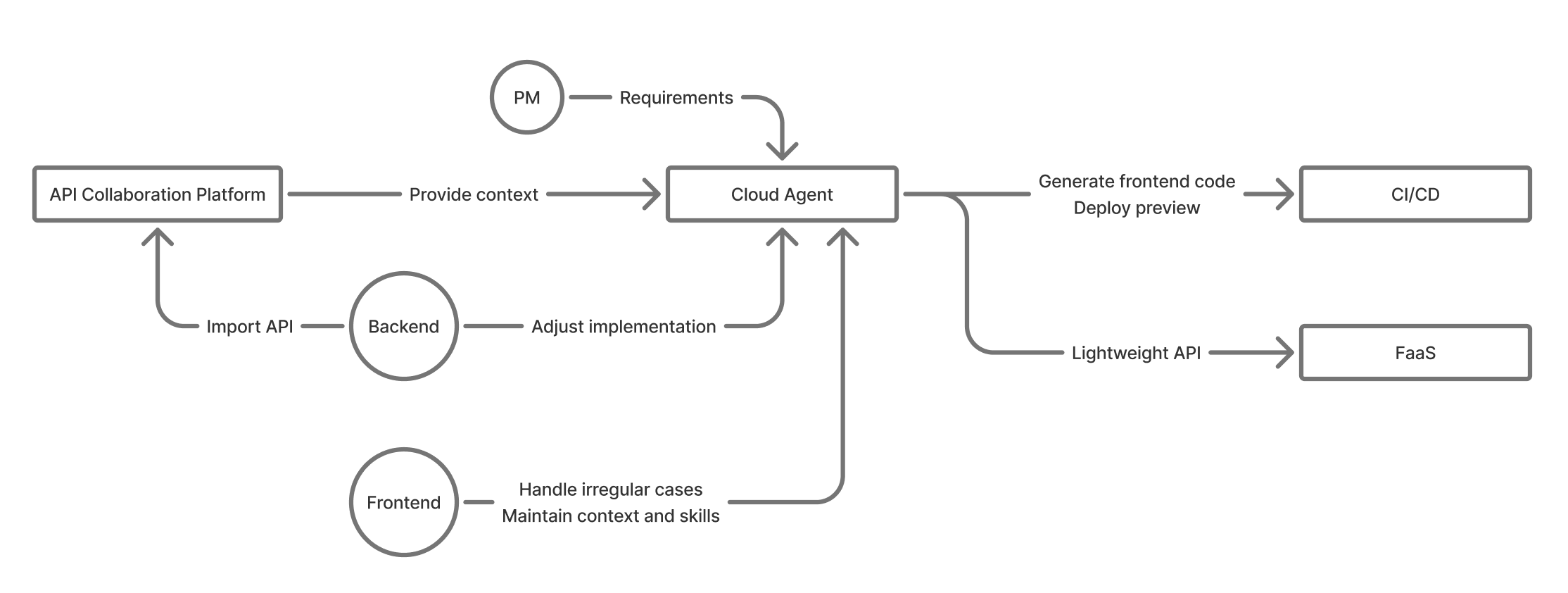
Product managers provide requirements in the collaboration platform. Backend engineers can import API definitions, handle integration work, and adjust implementation details. Frontend engineers maintain common capabilities and handle edge cases. The Cloud Agent receives this context, generates frontend code, deploys previews, and can also iterate on lightweight APIs at lower cost.
In this project, I built two IM agents one after another.
The first one used a fixed process:
User selects a git repository
-> clone
-> modify according to the prompt
-> deploy to a preview environment
-> user gives feedback and iterates
-> create a PRThis workflow had many limitations. It assumed that the user already knew which repository to modify. It also assumed that a task mostly happened in one repository. If a requirement involved multiple repositories, or if the agent needed to explore the codebase before deciding where to make changes, this workflow could not handle it well.
So I later built a second one with much more freedom. It can perform any allowed operation based on the user’s prompt: clone any repository within scope, inspect code as needed, deploy preview environments at any time, and add context during the task. This agent is clearly more capable.
But something interesting happened: backend engineers still preferred the first one.
Not because they disliked powerful agents. The reason was that the first agent wrapped frontend development and deployment into a predictable path. Backend engineers may not know which frontend repository to clone, how to start it, how to deploy it, or when to create a PR. The fixed workflow had many constraints, but it turned unfamiliar steps into buttons and states.
The second agent was more flexible, but flexibility also meant that users needed to know how to describe a more complete task, when to ask for deployment, how repositories relate to each other, and even some common problems in frontend engineering. For frontend engineers, that freedom is power. For users who do not know the frontend workflow, it can become a burden.
That experience made me more convinced of one thing: agents are not better just because they are more autonomous. Autonomy is not a number to maximize blindly. It is a cost. It solves the problem of workflows that cannot be fully defined in advance, but it also changes stability, cost, control, and failure modes.
Many products start with an LLM and naturally want to turn it into an agent. Ideally, it should plan by itself, call tools by itself, find problems by itself, and fix them by itself. More autonomy sounds more advanced. It sounds more like the future. But in real projects, we should think about which parts of autonomy actually help the user.
Anthropic’s Building Effective Agents makes a useful distinction between workflows and agents:
- Workflow: LLMs and tools run through code paths defined in advance.
- Agent: LLMs decide their own process and tool usage at runtime.
This distinction is helpful because it removes some of the mystery around agents. Workflow and Agent are not old versus new. They are not low-level versus advanced. They simply put the responsibility for deciding the next step in different places.
A Simple Task
Suppose we have a typical task:
Read a webpage -> extract information -> generate a report
For example, given a URL, the model should read the page, extract the author, publication time, main arguments, key data points, and useful quotes, then produce a structured report.
There are three ways to implement this task.
The first one is a fixed workflow:

Here the LLM only handles two clear subtasks: extracting information according to a schema, and writing a report from structured data. Fetching the page, cleaning the text, validating the output, and retrying errors are all controlled by code.
The second one is a fully autonomous agent:

Here the code only provides tools and a loop. The model decides what to do next.
The third one is a semi-fixed workflow:

The overall process is still fixed, but some local steps allow model autonomy. For example, during the “read and extract” step, the model may decide whether it needs to open secondary pages, search for original sources mentioned in the page, or gather additional context. But it must stay within a budget, return a specified schema, and pass checks in code.
All three approaches can complete the task, but they have very different engineering properties.
Put Freedom Where It Matters
It doesn’t mean that fixed workflows are bad, or that autonomous agents are always better. The useful design is usually somewhere in between: make the stable parts stable, and put freedom only where the task really needs judgment.
In the webpage example, fetching, validation, report format, and budget control can stay in the workflow. The part that needs freedom is reading the page: deciding whether the content is complete, whether to open related links, whether to use a browser, and whether there is enough evidence.
This keeps the user-facing experience predictable, while still giving the model room to solve cases that cannot be written as a simple script.
Back to IM Agent
Back to the IM Agent platform, the clearest improvement is multi-repository editing.
The first agent required the user to choose one repository before the task started. That made the workflow simple, but it also fixed an important decision too early. Many frontend changes are not isolated in one repository.
The second agent can clone any repository in scope, so it has the raw ability to solve this. But asking users to directly prompt a free agent is still too much. Backend engineers may not know which frontend repositories are related. They also may not know whether a change should happen in the application, a shared package, or both.
So I would keep the workflow entry fixed, but move repository selection into an agent step:
Requirement context
-> agent proposes related repositories
-> user confirms the repository set
-> agent edits multiple repositories
-> checks run per repository
-> user reviews one combined change summaryThis gives us the useful freedom from the second agent without losing the predictability of the first one. Users still start from a clear workflow. They do not need to know the repository map in advance. The agent gets freedom exactly where fixed workflow was too weak: discovering and coordinating changes across multiple repositories.