The Build System with Efficiency and Security
Background
In the modern software development process, we are inevitable to use automated build systems to improve efficiency and reduce labor costs. There are various types of build systems:
Build System Types
CI/CD System
CI/CD system may be the most well-known build system.


There are many CI/CD systems, SaaS or self-hosted applications, paid or free. We use CI/CD for our development every day. It chains the building, testing, and deployment of projects in an automatic way.
Develop -> Commit -> Build -> Test -> Deploy
Online Judge System
The Online Judge systems are originally set up for students who participate in algorithm contests like the Olympiad in Informatics (OI) or the International Collegiate Programming Contest (ICPC). And now it’s also widely used for interview practice (eg. LeetCode). It usually limits the memory and time cost, accepts users’ code, input test cases, and compare the output data with the correct answer.
Cloud AI Training Platform
AI model training takes a lot of resources and time, there are also many platforms to train your own model. You can upload data and the program/hyperparameter, it will do the rest thing for you.
Migration Platform
You may have used Dependabot or other similar things to update your dependency automatically. The migration platform has more powerful features. It allows library maintainers to create migration scripts in developers’ projects, and developers can subscribe to the migrations. When it satisfies the prerequisite of migration, the platform will run the migration script in the server, and create a pull request in the repository.
Features
All of those systems have the same features:
- They execute programs created by users;
- Tasks are not intended to be finished immediately.
Problems
Because of the features, we have some common problems to set up build systems. For example, we may have security concerns due to the user-defined procedures and schedule the tasks asynchronously. Now let’s dive into deep.
Privilege Escalation
Privilege escalation is one of the most serious vulnerabilities in software. In the early years, many online judge systems (OJ) were maintained by students or part-time volunteers. So there was a lot of data leaked from OJ. For example, there were two famous OJ Tyvj and BZOJ, which problems and test cases are all leaked. The former was turned down after this attack. To prevent these accidents, there are many approaches that help us to improve security.
Separated Worker
Some developers deploy their web servers and build workers on the same machine. It brings the risk that users’ programs may access the resources on the web server directly. By separating workers and web servers, you can restrict only a few interfaces that are accessible from workers.
Docker
However, it only isolates the worker from web servers, the data in the same worker is still not guaranteed to be safe. Around 2014, Docker became more and more popular as OS-level virtualization. Before Docker, we may use a virtual machine implementation like Vagrant or VMWare to do the same thing. But now, there is no doubt that Docker is the mainstream of virtualization. With Docker, you can isolate every task in a container, so that it won’t affect any other tasks.
However, for efficiency concerns, we may still put some tasks in the same container to improve the build speed. For this case, we can assign tasks from the same user, or run them as different Linux users to reduce the potential security problems. We’ll talk about it later.
Resource Exhaustion

The second most happened vulnerability in build systems is resource exhaustion. Our resource is limited, so if a user submits a fork bomb, or allocates too much memory, other tasks will be blocked and causes denial of service.
Docker
Docker also has the ability to limit resources used in containers. We can limit the CPU, GPU, memory, network, and mounted files.
Besides that, we may also need to limit resources inside the container (eg. Reuse the container for several tasks).
CGroups
CGroups is a Linux kernel feature that limits resource usage for processes. It can also be used to measure resource usage. It’s useful if you want to run a benchmark inside the system or charge your customers by resource usage. Docker also uses CGroups inside.
Here is another high-level tool based on CGroups to run a program with limited resources. lrun
% lrun --max-cpu-time 1.5 bash -c ':(){ :;};:' 3>&1
MEMORY 10461184
CPUTIME 1.500
REALTIME 1.507
SIGNALED 0
EXITCODE 0
TERMSIG 0
EXCEED CPU_TIMEOther
There are many other methods to limit resources in specified situations. JVM for Java, V8 for JavaScript, and other runtimes for its programming languages have the option to limit resources.
Improvement
Thanks to the ability of Docker, we can get rid of privilege escalation and resource exhaustion in most cases. But we can still optimize our systems further.
Cache
There are many repeat procedures in tasks. We can save much time if the repeat procedure can be skipped. Roughly, there are two types of cache, the system-level cache and the user-defined cache. The system-level cache is transparent to users, caches some general resources. While the user-defined cache is specified by users, caches special products from tasks.
System-level Cache
System-level Cache, for example:
- Base image, you can put all common things in the docker image;
- Docker layer cache, if you build docker image in the task;
- Package manager cache (npm, Maven, PyPI, …), depends on your project type;
- …
User-defined Cache
The most system-level cache can also be implemented as a user-defined cache. For example, GitLab supports users to define their own cache.
cache-job:
script:
- echo "This job uses a cache."
cache:
key: binaries-cache-$CI_COMMIT_REF_SLUG
paths:
- binaries/Implementation
For different types of cache, there are also various implementations for them.
In-place Cache
In-place cache means that we just keep the files that should be cached there. It’s the simplest implementation but with many limitations.
- Tasks with the same type should be handled in the same container, or the cache won’t hit;
- Tasks with different types must not be handled in the same container, or it will lead to some unexpected results;
- It’s difficult to control the invalidation of a cache;
- It can’t store different versions of the cache.
Cache in Docker Volumes
If we want to share the cache between workers, we can mount the Docker volumes to cached directories. So we can decide which volumes to mount when running the docker container, and use it flexibly. It also has some limitations:
- Volumes are different filesystems in containers, some features are disabled when crossing filesystems (eg. hard link);
- Volumes can only be shared in one machine, or we need to use an NFS;
- Files in the same volume may have conflicts when multiple tasks are using them at the same time.
Cache in Remote Storage
The “remote” is relevant to the working directory, we can also put them into the Docker volumes. The difference is that we don’t use the stored files directly, but copy them into the working directory and do the rest. It avoids the conflict between different tasks and supports sharing cache among all containers wherever they are. But the shortage is that we should upload & download cached files every time, which may take a lot of time.
Self-hosted Registries
In CI/CD systems, we spend time downloading dependencies from registries (npm, Maven, PyPi, …). Despite we have cached many dependencies, there are always some dependencies not cached or invalidated. It’s good to host registries in the private network to boost the dependency installation. Most companies have their own registries.
Summary
There are many approaches to cache files for tasks. In practice, you can combine many methods to work together. It depends on your system.
Cold Start
A docker container usually takes several seconds to start. It’s OK for tasks that take minutes or more. But for some short tasks, the delay is significant and worth reducing. (eg. Tasks in OJ systems usually less than one second.) We can reuse a container for the same type of tasks, distinguished by its user, project, or other symbols. Because there are fewer risks to sharing a container among tasks created by the same user, we can improve the speed at the same time.
Alternative Container Tools
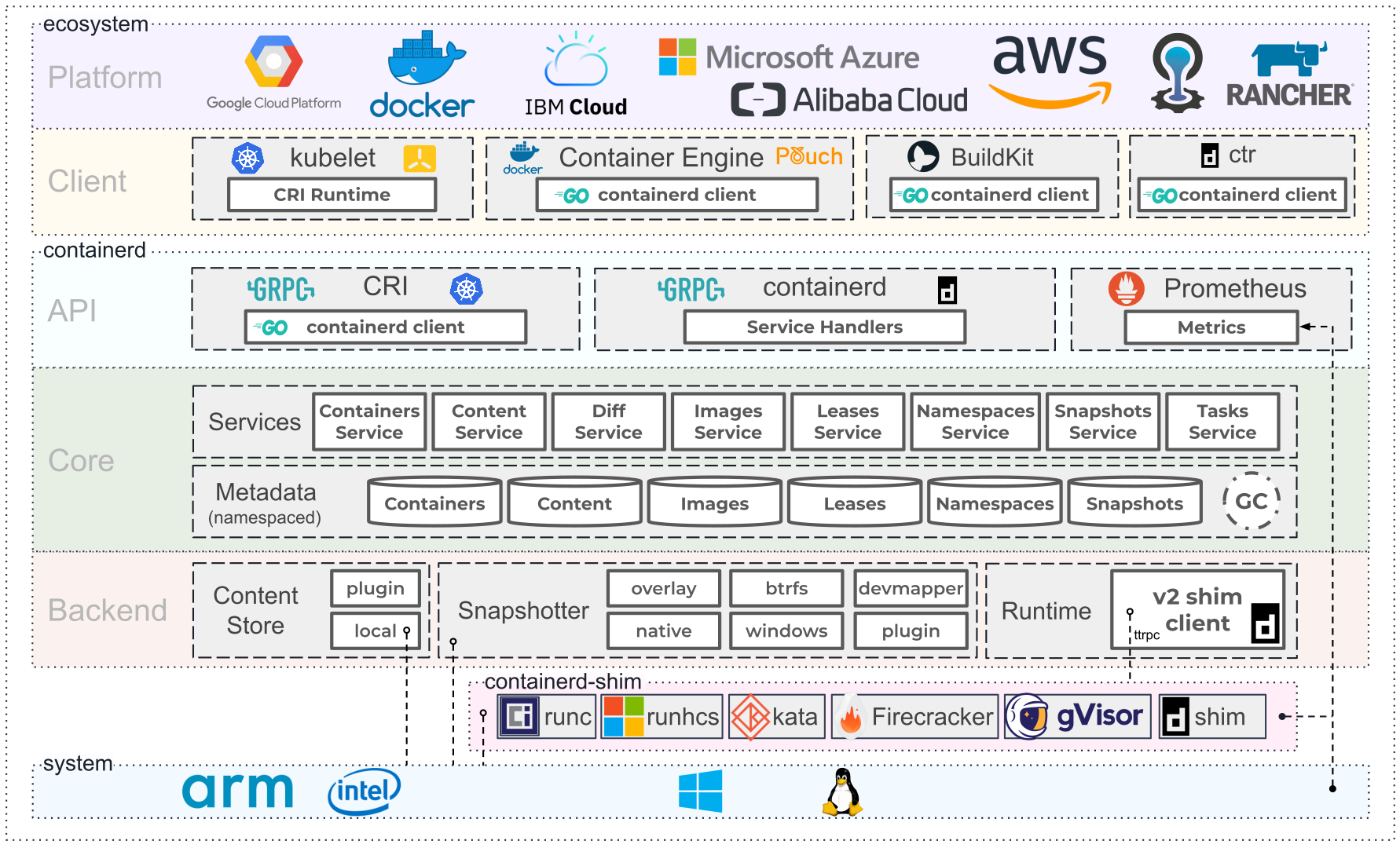
We use docker directly most time. But if you don’t need all features provided by Docker, and want a millisecond-level optimization, you can try to use a low-level tool for containers like containerd or runc.
Task Scheduling
Another topic for build systems is task scheduling. All tasks in build system are asynchronous and may need a lot of resources. It’s important to manage them in a distributed way with good strategies. We can use Kafka, RabbitMQ, or some Redis-based queue (Celery, Bull, …) to manage async tasks.
Cache Hit Rate
If we are using an in-place cache, or the cache is stored in a machine, it’s better to assign similar tasks to the same machine to increase the cache hit rate. We can send those related tasks to the same partition to ensure they are handled by the same worker.
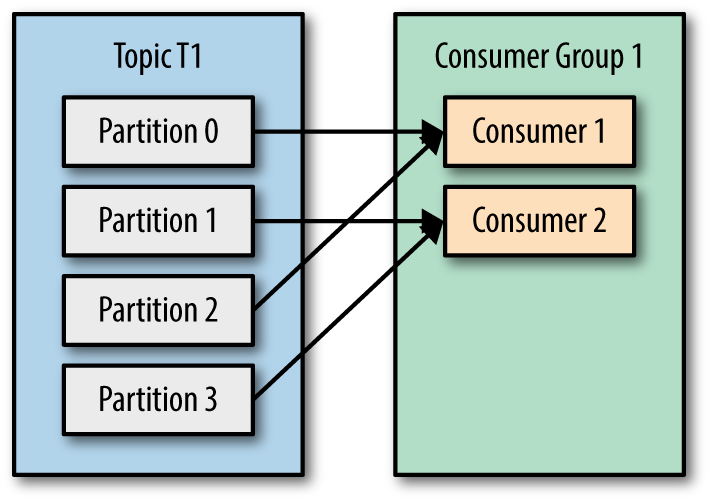
For those who are not familiar with Kafka: Kafka has topics to organize messages (like message channels), every topic has one or more partitions. Every partition is assigned to a consumer (but a consumer can have many partitions).
Horizontal Scaling
A build system can have many tasks to build parallelly so we can’t handle all of them in a single worker. It will be a disaster if we maintain connections between the web server and workers manually.

For every new worker, we should know its network location and establish a connection to it. We can also use service discovery to register workers automatically, but a message queue can do it for us.

Kafka has brokers to arrange all these tasks, dispatch them from the web server to workers and balance the load. It replicates data inside and balances workers when some of them are down, which makes it more reliable.
Summary
Here I talked about some points to designing a build system with efficiency and security. But in practice, we should also think about the features of the system like data scale, concurrency, time cost, dependent resource, etc.
References
- https://containerd.io/
- https://github.com/quark-zju/lrun
- https://docs.gitlab.com/ee/ci/
- Some images are from the Internet