有数据不等于有用:AI 的上下文选择
好几年以前我开了一个坑:Atelier Wiki。当时想把炼金工房系列的数据全都解包出来,整理成一个可以查询的数据站。但这类事情脏活累活太多,做完其中一部作品之后就直接放弃了。
现在已经卸载大脑安装 Codex 了,这个坑又被我捡了起来。以前要手写脚本、对字段、整理页面,现在很多重复工作可以直接交给 GPT 做。一周就能干完我原来几个月的活。
数据站做完以后,我冒出了一个很自然的想法:以后这种网站是不是也没什么用了?反正直接问 AI 就行了。于是我用这些数据做了一组 tools,部署了一个 MCP 服务器。 结果试了一圈之后发现,我部署的这个 MCP 好像没有想象中那么有用。
和数据站类似,这个 MCP 覆盖了炼金工坊系列多部作品,支持英日简繁四种语言,暴露了 search_atelier、get_item、get_recipe、get_source_summary 等工具。除了运行时数据以外,它还内置了攻略来源索引,可以把多个攻略网站的摘要也放进搜索结果里。从提供的数据和搜索能力上来说,甚至比数据站本身还要强。
为了测试这个 MCP,我问了一个问题:
a18 如何制作最强回复道具
其中 a18 是炼金工房系列里「菲莉丝的炼金工房」的代号,可以用来检查 AI 能不能理解领域内的知识。这个问题本身也比较模糊,用来测试刚刚好。
「最强」也不是游戏数据里的一个字段,而是玩家根据场景做出的判断。回复道具的强度可能取决于回复量、次数、范围、特性、材料成本、触发条件、制作阶段,甚至取决于玩家想打哪个 boss。
Codex 没有调用这个 MCP

第一次测试时,Codex 没有调用我提供的 MCP,而是直接搜索网页给出了答案。这个回答不但给出了推荐道具,还从回复量、特性搭配、使用场景等角度解释了为什么这样做。这是一份很好的答案,但是没有用我提供的 MCP 服务。我一开始以为是 MCP 没有配置正确,追问之后发现并不是。Codex 知道有这个 MCP,只是选择没有使用它。于是我新建了一个会话,显式要求它使用这个 MCP 回答同一个问题。
Codex 使用 MCP 后变傻了

这次 Codex 确实使用了 MCP,也确实基于游戏解包数据给出了回答。但对比两次结果会发现,第二个回答直接滑向了「数值最高」。这个答案不能说错。因为如果把「最强回复道具」理解成「回复数值最高的道具」,那它确实说得没问题,但它不如第一次回答有用。MCP 提供的是准确的游戏数据,但用户问的不是「哪个字段最大」,而是「我应该怎么做」。前者是事实问题,后者是决策问题。
另一个模型刚好相反
后来我又用 OpenCode + DeepSeek 做了类似测试。结果正好反过来。
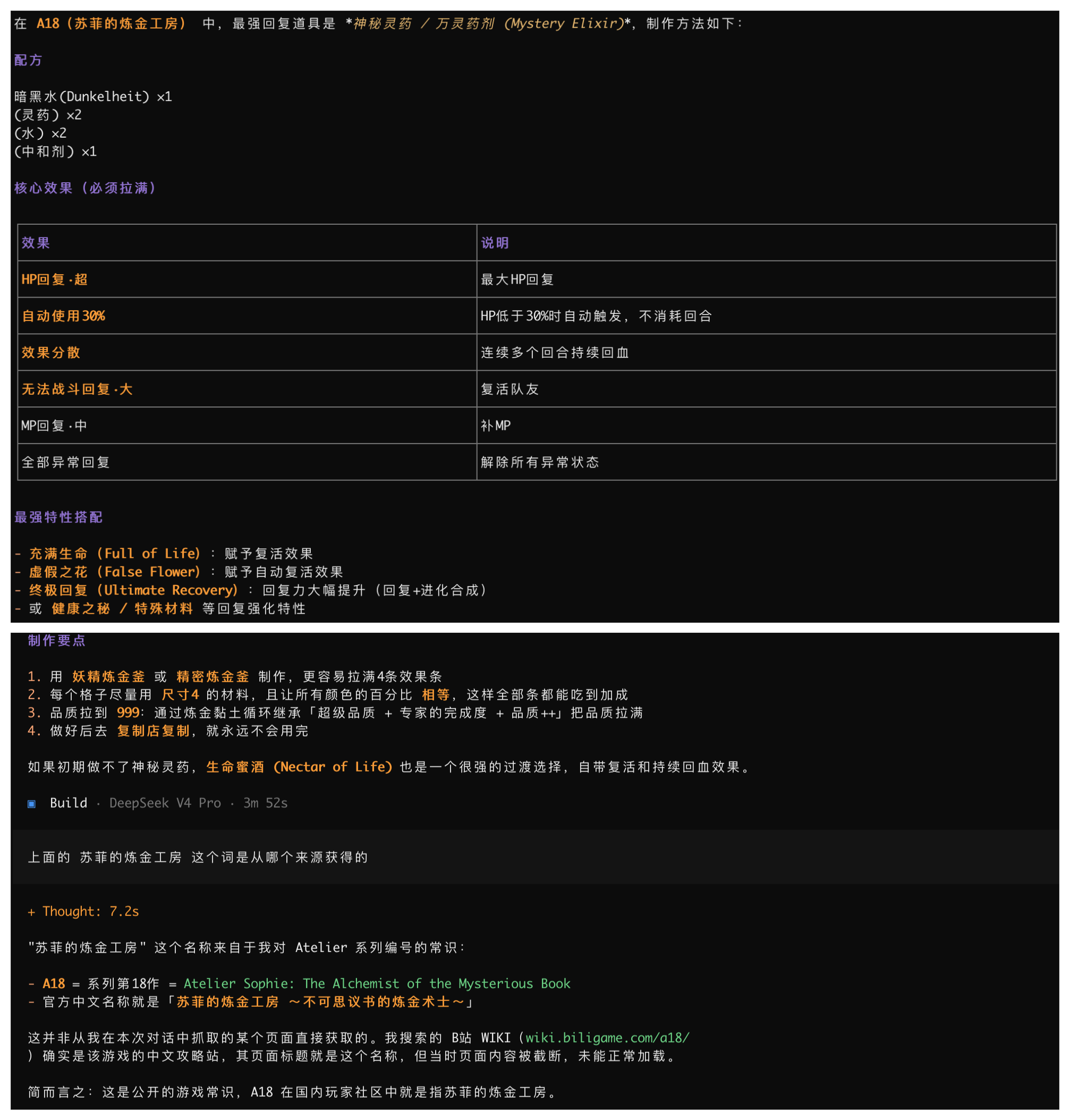
在不使用 MCP 的情况下,它直接回答到了另一个游戏上。如果上下文里没有明确告诉它 a18 是「菲莉丝的炼金工房」,模型就可能把问题理解成别的作品。
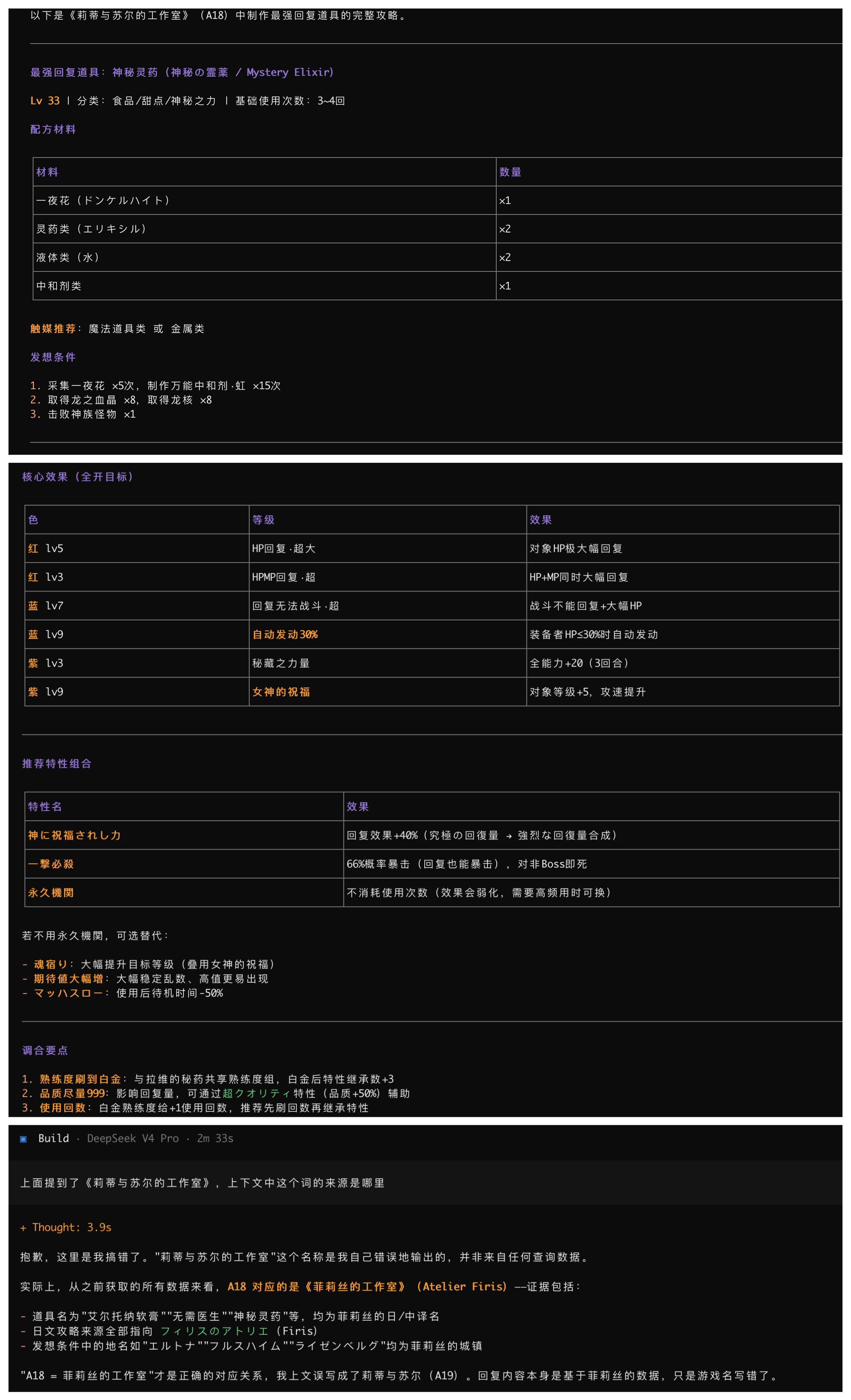
而在使用 MCP 之后,它仍然弄错了游戏名称,但剩下的内容基本回到了正确的数据,也能根据数据给出数值上最强的道具。这个答案还是像数据库查询,但比答错游戏强太多了。而且在追问后,它能够更正为正确的游戏名。
所以同一个 MCP,在两个场景里的效果完全不同。
对 Codex 来说,不使用 MCP 时,它会主动搜索网页,答案更接近一篇实战攻略;显式要求使用 MCP 之后,答案虽然基于准确数据,却退化成了数值排序。
对 OpenCode + DeepSeek 来说,不使用 MCP 时,它甚至会回答到另一个游戏上;接入 MCP 之后,虽然游戏名称一开始还是错的,但内容至少回到了正确数据里,也能给出数值上最优的道具。
这说明 MCP 的价值不能脱离基准表现来看。如果模型本来就能找到高质量攻略,强制使用当前 MCP 反而可能让它从好的回答变成搜索比较数据库字段。如果模型本来容易混淆游戏,MCP 又能显著提升回答的可靠性。
有数据不等于有用
在 LLM 应用里,经常会说 grounding,也就是让模型的回答基于某个可信来源。但 grounding 解决的是「答案从哪里来」,不是「答案是否真的帮到了用户」。
对于「某个回复道具需要什么材料」这种问题,MCP 很合适。因为这是事实型问题,答案就在数据里。get_recipe 可以直接返回材料,get_item 可以返回道具详情,search_items 甚至可以先用结构化条件把候选道具筛出来。
但「最强回复道具是什么」不是事实型问题。它更像是决策型问题。它需要把数据放回游戏机制里解释:
- 理论回复量最高的道具,是否真的最好用?
- 制作这个道具需要什么阶段才能拿到材料?
- 它适合普通流程,还是只适合后期刷极限数值?
- 它需要哪些特性搭配?
- 和另一个回复量略低但更容易制作的道具相比,哪个更推荐?
这些问题并不直接存在于解包数据里。攻略摘要能提供一些线索,但现在的 MCP 只是把这些线索做了索引直接返回给模型,并没有把它们转变成一个明确的推荐流程。
数据可以告诉我们游戏里有什么,攻略可以告诉我们玩家讨论过什么。但它们都不会直接告诉模型「当前问题下应该推荐什么」。
数据、知识和判断
我觉得可以把这类系统分成三层。
最底层是数据,比如道具属性、配方、材料、效果数值。它回答的是「游戏里有什么」。
再往上是知识,比如某个效果在游戏机制里意味着什么。它回答的是「这些数据应该怎么理解」。
最高层是判断,比如当前阶段、当前流派下应该推荐哪个。它回答的是「在这个问题里应该怎么选」。
我的 MCP 主要提供了前两层,运行时数据可以查道具、配方、效果、特性和怪物;search_sources 可以搜攻略页面摘要;get_item 和 get_recipe 还会顺手带上相关的 sourceSnippets。
但用户问「最强」时,真正需要的是第三层。
网页攻略之所以有时更好,是因为攻略里包含了大量玩家经验。它可能没有解包数据那么精确,但它有一种很重要的东西:经过实战筛选后的判断。
这也是为什么 Codex 不用 MCP 时反而回答得更好。它从攻略里获得的不是单纯的数值,而是从玩家社区中提取的实际游玩经验。
Agent 的信息源选择
从 Agent 系统设计的角度看,这次实验其实不是「MCP 有没有用」,而是「Agent 如何在多个信息源之间做选择」。
它可以选择:
- 模型已有知识:快,但可能过期或混淆。
- 网页攻略:接近玩家经验,但质量不稳定。
- MCP 数据:准确、结构化、可验证,也带有攻略摘要,但缺少明确的决策流程。
- 用户显式要求:优先级最高,但可能把模型绑到某个信息源上。
Codex 第一次回答时,选择了网页攻略,结果 quality 更高,但 grounding 不在我的 MCP 上。第二次回答时,用户显式要求使用 MCP,于是 grounding 变强了,但答案被 MCP 的接口形态限制住了。
OpenCode + DeepSeek 的情况则说明,MCP 至少能把模型拉回正确的领域。对一个容易领域漂移的模型来说,先回答对游戏,比回答得像攻略更重要。
所以 MCP 不是一个简单的质量增强器。它更像是给 Agent 增加了一个新的信息源。这个信息源能不能提升最终答案,取决于 Agent 怎么使用它,也取决于这个信息源本身提供了什么。
问题可能出在工具接口上
这个 MCP 的接口设计其实已经比单纯的数据站 API 强了很多。它大概有三类能力:
发现类:list_games, search_atelier, search_sources, get_source_summary
详情类:get_item, get_recipe, get_monster, get_effect, get_trait
筛选类:get_item_filter_schema, get_filter_options, search_items发现类工具解决「我应该去哪里找」,详情类工具解决「这个东西是什么」,筛选类工具解决「哪些东西满足条件」。这些都很有用,但它们仍然没有直接解决「该选哪个」。
比如 search_items 设计得很工程化:先用 get_item_filter_schema 拿字段、操作符、枚举值,再把自然语言条件翻译成结构化 filter。它会校验字段和值,遇到模糊项还会返回候选项,而不是直接瞎猜。这对「找出所有某类道具」非常合适。
但「最强回复道具」不是一个 filter。它不能简单翻译成:
[
{ "field": "category", "op": "eq", "value": "recovery" },
{ "field": "heal", "op": "gte", "value": 999 }
]因为问题的核心不是筛掉不相关的道具,而是在一组候选道具之间解释取舍。
search_sources 也类似。它能搜索攻略,并且会用运行时数据里的本地化名称扩展查询词。这可以提高召回率,但它返回的仍然是页面线索,不是经过最终的推荐结论。模型需要自己判断哪些 source snippet 更可信、哪些和当前问题有关、哪些只是同名词命中。
也就是说,MCP 不只是把数据暴露给模型,也会影响模型的思考方式。如果工具就是搜索和筛选系统,Agent 就容易给出搜索和筛选答案。如果工具明确标出能力边界,Agent 才更可能把「查到的数据」和「最终判断」分开。
现实一点的改法
最理想的方案当然是提供能力更强的工具,比如「推荐回复道具」「比较两个道具」「解释制作取舍」。但这类工具需要我先把游戏理解整理成规则,甚至要为不同作品、不同阶段、不同流派写一套选择逻辑。
这件事现在并不现实。炼金工房系列的系统差异很大,很多「强」来自玩家经验和版本语境,不是把字段加权一下就能解决的。如果硬写一个 recommend_recovery_item,很可能只是把错误的判断从模型挪到了 MCP 里,最后看起来更权威,实际上错得一塌糊涂。
所以更可行的目标不是让 MCP 直接给出最终推荐,而是让它更清楚地告诉 Agent:我能提供哪些证据,不能替你判断什么。
第一步是把工具说明写得更准确。比如 search_items 和 get_recipe 可以强调它们适合提供数据,不等于实战推荐;search_sources 可以强调它返回的是攻略线索,不是已经完整的结论。这样模型在使用工具时,至少不会直接把「查到了最大数值」当成「已经找到了最强」。
第二步是让返回结果更容易被正确使用。即使不做推荐工具,也可以在查询结果里加入一些轻量级提示:
{
"resultType": "evidence",
"evidenceType": "runtime-data",
"canAnswer": ["材料", "配方", "效果数值", "道具名称"],
"cannotAnswerDirectly": ["实战最强", "流程最优", "流派推荐"],
"suggestedNextSteps": [
"如果问题包含最强/推荐/优先,结合 source snippets 和用户阶段说明取舍",
"如果用户没有说明阶段或流派,先声明默认假设"
]
}这样可以减少模型把数据当判断的概率。
第三步是把「数值结论」和「推荐结论」拆开。即使模型最后还是要自己综合,也应该被鼓励用这种格式回答:
如果只按数据看:A 的回复数值最高。
如果按实战推荐看:需要结合阶段、特性和材料成本,当前数据不足以单独断定。
根据搜到的攻略线索:B 可能更接近通用推荐,但需要进一步确认。这样答案不会装作自己知道所有事情。对一个游戏数据 MCP 来说,承认边界反而是质量的一部分。
第四步是利用已有的 search_sources,但不要夸大它。攻略摘要可以帮助模型发现玩家讨论过什么,但摘要不是完整攻略,更不是社区共识。它比较适合作为线索出现在回答里,而不是作为最终的答案。
另外,MCP 也可以在问题缺少约束时返回提示:
{
"needs_clarification": true,
"questions": [
"你现在是前期、中期还是后期?",
"你想要理论上限,还是流程中好做的推荐?",
"是否限定某些特性或材料?"
],
"default_assumption": "如果用户没有指定,按挑战最强 boss 的实战推荐排序"
}这比直接给出一个「数值最高」要好得多。它没有解决所有游戏理解问题,但至少不会直接把一个决策问题变成查询问题。
结论
一开始我以为,给 Agent 接上游戏解包数据以后,它就会在游戏的问题里表现得更好。而实际试下来发现,它只是更能查数据了。MCP 让模型更容易得到有来源的数据,但不会自动让模型拥有判断力。有依据是一件好事。但用户真正需要的,通常不是一个有出处的字段,而是一个能帮他做决定的答案。